

![]()
Hadoop Distributed File Syste의 약자
HDFS는 Hadoop이 각광받게 된 대표적 이유중 하나로 수십 테라바이트, 페타바이트 이상의 대용량 파일을 분산된 서버에 저장하고 저장된 데이터를 빠르게 처리할 수 있는 블록구조 파일시스템입니다. 파일을 특정크기의 블록으로 나누어 분산된 서버에 저장하는 것이 특징이고 블록의 크기는 기존에는 64MB였지만 Hadoop 2.0 부터는 128MB로 증가되었습니다.
1. 장애복구
2. 스트리밍 방식의 데이터 접근
3. 대용량 데이터 저장
4. 데이터 무결성
HDFS의 구조는 다음과 같습니다. HDFS는 기존의 우리가 쓰는 파일시스템과는 완전히 다른 구조로, 하나의 Name node, 하나의 Secondary Name Node와 여러개의 Data node로 이루어져 있습니다.
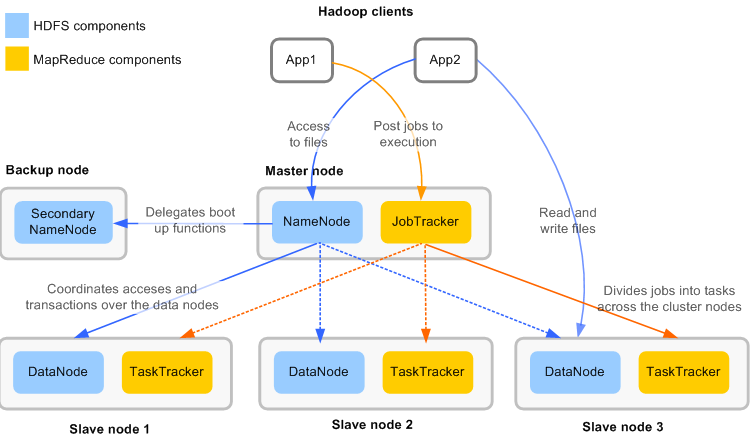
각각의 노드의 역할에 대해 자세히 살펴보겠습니다.
Master
HDFS는 기본적으로 Master-Slave 시스템을 따르고 Name node가 master의 역할입니다. 따라서 Name Node가 죽으면 시스템 전체에 영향이 가게 됩니다. Slave 역할의 Data node에게 I/O작업을 할당하는 것이 Name node의 역할입니다.
데이터의 위치정보 담당
Name node는 현재 파일 시스템이 가지고 있는 블럭에 대한 매핑 테이블을 가지고 있습니다.
Name Node 장애복구 해결 전략
- Secondary Name Node 운영
- Hadoop 2.x 부터는 한쌍의 Name Node를 활성화-대기 상태로 구성하여 HDFS HA를 지원(약간의 아키텍쳐 변화 필요)
- 이에 대한 자세한 설명은 밑에서 다시 진행합니다.
Name Node의 백업 용도
Secondary Name Node라는 이름 덕분에 Name Node가 죽으면 그 역할을 대신 해 줄 수 있을 것 같지만 그렇지는 못합니다. Secondary Name Node는 read-only 로서 Name Node의 백업 용도로 Name Node의 운영에 도움을 주기위해 존재합니다.
EditLog 관리
반면 Secondary Name Node가 정말 Name Node의 단순 백업만 담당하냐 하면 그런것도 아닙니다. Secondary Name Node의 주 역할은 Edit log 가 너무 커지지 않도록 주기적으로 fsimage에 editlog를 병합하고 이를 Name Node에게 전달합니다. 만약 병합을 하지 않고 계속해서 로그들을 쌓아두면 메모리 크기보다 커져 문제가 발생할 수 있습니다.
EditLog: HDFS의 메타데이터에 대한 모든 변화를 기록하는 로그 파일으로 NameNode의 로컬에 저장됨
fsimage: Name node의 메모리 상태를 가지고 있는 파일
실제 데이터 저장
Data Node라는 이름처럼 실제 바이너리 파일은 블록단위로 쪼개져 Data node에 들어가 있습니다.
Slave
데이터 요청에 대해 Name Node를 반드시 거쳐 Data Node의 위치를 찾아 사용됩니다. 또 클러스터가 시작될 때, 로컬 디스크에서 변경사항이 생길때 Name Node에게 항상 블록정보, 변경사항 등을 보고하게 됩니다.
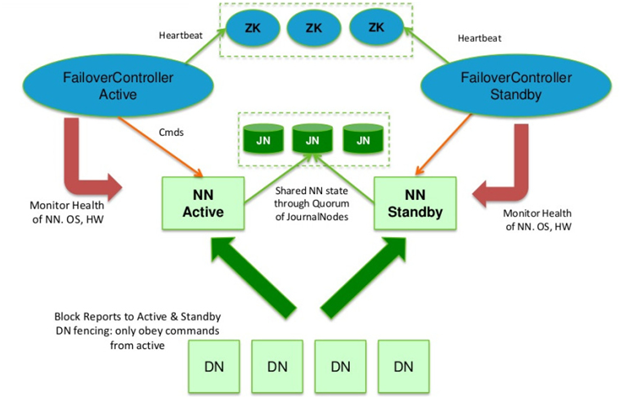
Name Node의 상태가 불능이 되면 전체 시스템이 마비가 되는 것을 방지하기 위해 Hadoop 2.x부터는 High-Availability를 제공하기 시작했습니다.
HDFS HA는 이중화된 두대의 서버 Active Name node(이하 액티브 노드)와 Standby Name node(이하 스탠바이 노드)를 이용하여 지원합니다. 액티브노드와 스탠바이노드는 데이터 노드로부터 블록 리포트와 하트비트를 모두 받아서 동일한 메타데이터를 유지하고, 공유 스토리지를 이용하여 edit파일을 공유합니다.
액티브 네임노드는 네임노드의 역할 그 자체를 수행하고, 스탠바이 네임노드는 액티브 네임노드와 동일한 메타데이터 정보를 유지하다가, 액티브 네임노드에 문제가 발생하면 스탠바이 네임노드가 액티브 네임노드로 동작하게 됩니다. 액티브 네임노드에 문제가 발생하는 것을 자동으로 확인하는 것이 어렵기 때문에 보통 주키퍼를 이용하여 장애 발생시 자동으로 변경될 수 있도록 합니다.
HA를 구성을하게 되면 공유 스토리지를 이용합니다. 만약 단일 스토리지라면 SPOF 문제가 발생할 수 있으며, 이 또한 시스템 전체의 문제로 번질 수 있습니다. 따라서 단일 공유 저장소 대신 JourmalManager를 두고 Journal node로 이루어진 분산 저장소에 fsimage와 editlog를 저장하고 동기화 시킵니다.
Journal Node : 액티브노드가 editlog를 기록하는 서버, 데이터 consistency 보장을 위해 3대 이상의 홀수대로 구성해야 함.(특정 노드 에러 시 과반 이상의 동일한 데이터 추출을 위해)
SPOF : Single point of failure, 한 point의 fail이 전체 시스템의 fail이 되는 것
Reference