

![]()
MapReduce(이하 MR)은 구글에서 발표되기 이전 수학에서 먼저 다뤄진 이론입니다.
Hadoop이 이목을 끌게 된 큰 계기이였고, Data engineering이 분산환경으로 들어오며 크게 각광받게 되었습니다.
기존에 MapReduce는 대용량 데이터를 잘게 쪼개 원하는 형태로 묶어내기 위한 최고의 플랫폼이었습니다. 하지만 지금은 해당 역할을 Spark가 그 자리를 완전히 대체하고 있습니다. 하지만 여전히 대용량 데이터 처리의 기저에는 MapReduce가 있기에 이를 한번쯤은 알아볼 필요가 있습니다.
MapReduce의 구성은 정말 이름 그대로 Map과 Reduce 입니다. Mapper를 통해 데이터를 매핑하고 Reducer을 통해 원하는 형태로 reduce한다는 매우 직관적인 이름을 갖고 있습니다.
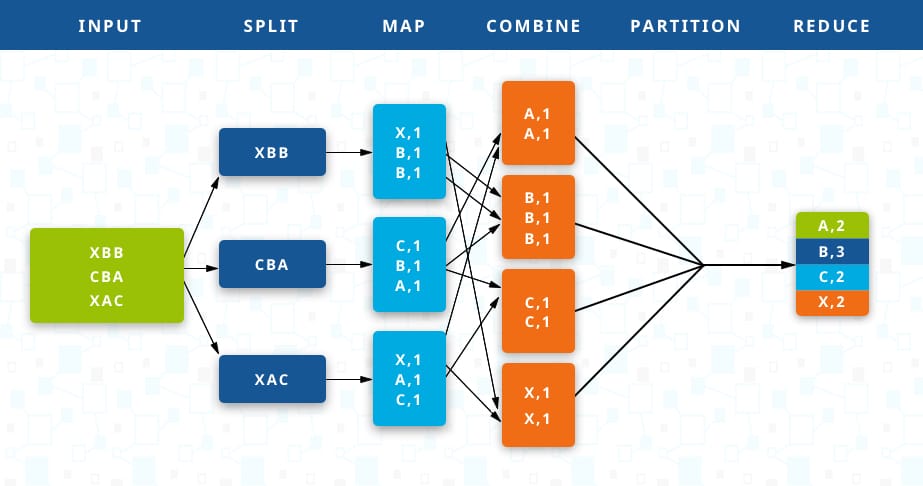
위의 그림의 예로 Combine에서와 같이 같은 키에 대해 모아야 하므로 aggregation을 위해서는 그 키가 필요합니다. 하지만 그 키가 어느 Mapper에서 나올지는 예측할수 없습니다.
따라서 refine(Mapper -> Reducer)의 프로세스에서 MapReduce의 성능이 가장 좌지우지되게 됩니다.
이 과정을 shuffle이라고 합니다. 보다 정확히 말하면 shuffle이란 메모리에 저장돼 있는 Mapper의 출력 데이터를 파티셔닝과 정렬을 수행한 뒤 로컬 디스크에 저장한 뒤 네트워크를 통해 Reducer의 입력 데이터로 전달되는 과정입니다. Shuffling에 대해서는 아래 그림이 굉장히 직관적으로 다가옵니다. TB이상의 데이터에 대해 sorting하고 merge하는 작업을 디스크 기반에서 수행하기에는 비용이 굉장히 큽니다. 따라서 계속해서 보완을 거쳐가다가 메모리 기반으로 눈을 선회했던 프로젝트의 결과물이 오늘날의 Spark입니다.

Reference