


HyperText Transfer Protocol
HTTP는 HTML과 같은 리소스를 가져오기 위한 프로토콜입니다. HTTP는 웹에서의 모든 데이터 교환의 기초이며, 수신자(대부분의 경우 웹 브라우저)측에서 요청을 보내는 client-server 프로토콜입니다. 가져온 하나의 완전한 문서는 가져온 sub문서들, 예를 들어 text, layout description, images, videos, scripts 등으로 재구성됩니다.
Data stream과는 대조적으로 Client와 Server는 개별적인 메세지를 교환하며 통신합니다. (많은 경우 웹브라우저인) client가 보내는 메세지를 우리는 requests라 하고 server가 보내는 메세지를 responses 라고 합니다.
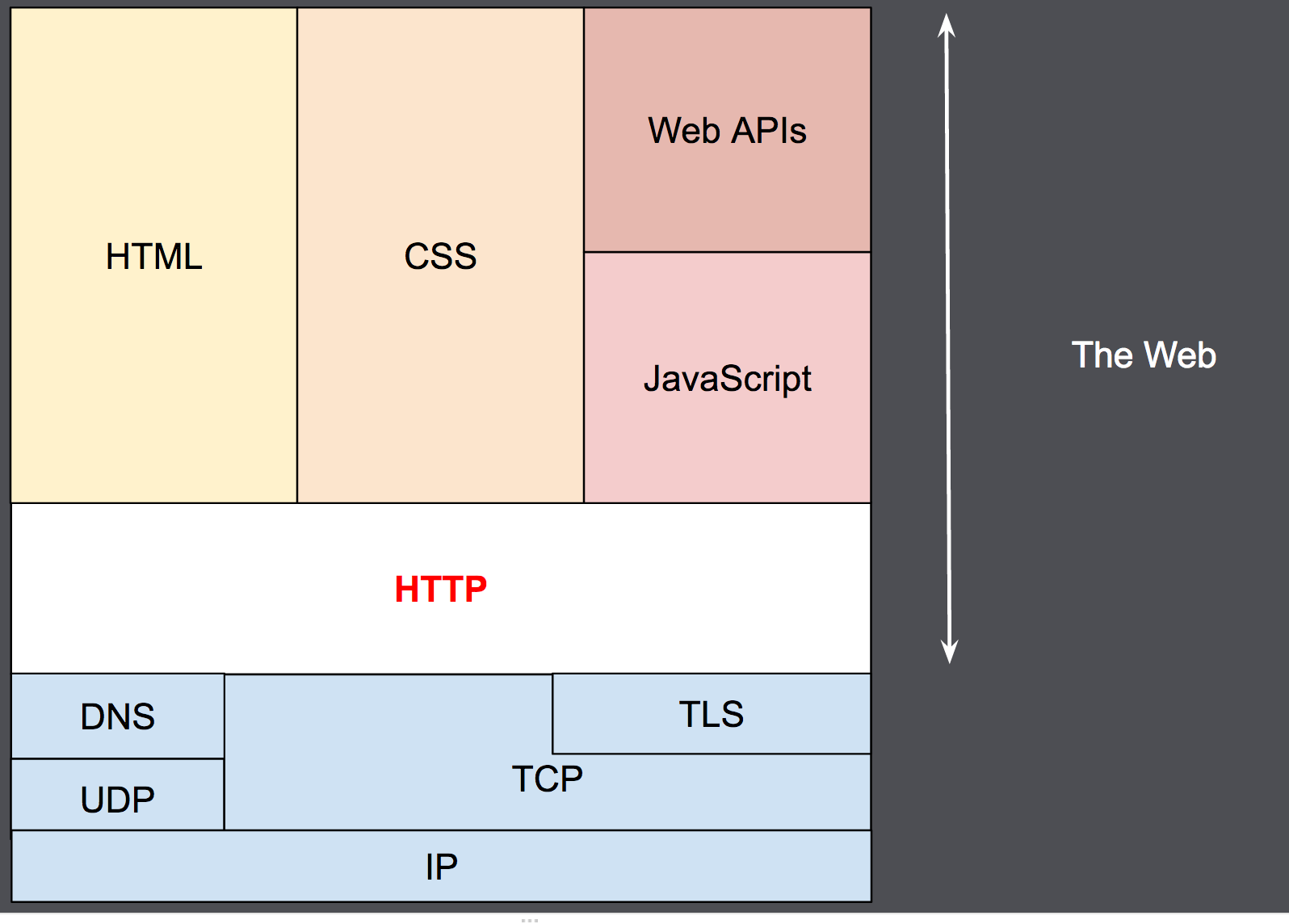
1990년대 초기에 설계된 HTTP는 계속해서 진화되어 온 확장가능한 프로토콜입니다. HTTP는 application layer의 프로토콜로 TCP, 혹은 암호화된 TCP 연결인 TLS를 통해 전송됩니다. 하지만 이론적으로는 신뢰할 수 있는 어떤 통신 프로토콜을 사용해도 무방합니다. HTTP의 확장 가능성으로 인해 HTTP는 hypertext 문서를 가져오는 것 말고도 사진이나 동영상을 가져오거나 HTML의 form 결과와 같은 컨텐츠를 서버로 post하는 것 또한 가능합니다. HTTP는 웹에서 필요 시 문서의 일부만 업데이트 하기 위해 가져오는 것도 가능합니다.
HTTP는 client-server 프로토콜입니다. 요청은 한 entity, user-agent (혹은 proxy가 대신)에 의해 보내집니다. 대부분의 경우 user-agent는 웹브라우저이긴 하나 다른 어떤것도 될 수 있습니다. 예로 검색엔진 인덱스를 넣고 유지하기 위한 크롤링 bot이 될 수도 있습니다.
각각의 request는 서버로 보내지게 되고 서버는 요청에 대한 대답을 만들어 response라는 이름으로 제공합니다. client와 server 사이에는 여러 개체들이 있는데 예로 다양한 작업을 수행하고 게이트웨이로서의 역학 혹은 캐시 역할을 하는 proxy 등이 있습니다.

현실에서는 client와 server 사이에 요청을 처리하기 위한 더 많은 컴퓨터가 있습니다. (라우터, 모뎀 등등) 웹의 계층화된 설계 덕분에 이러한 것들은 network layer, transport layer에 숨겨져 있습니다. HTTP는 최상위의 application layer에 있습니다. 하위계층들의 경우 네트워크 문제를 진단하는 데에는 중요하지만, HTTP 명세와는 관련이 없습니다.
user-agent는 사용자를 대신해서 동작할 수 있는 모든 도구가 될 수 있습니다. 주로 웹브라우저이고 엔지니어나 웹 개발자가 사용하는 디버깅을 위한 프로그램일 수도 있습니다.
브라우저는 항상 요청을 보내는 개체입니다. 절대 서버가 될 수 없습니다.(서버에서 초기화하는(보내는) 메세지를 실험하는 몇몇 메커니즘이 몇년동안 추가되었긴 합니다.)
브라우저는 request를 보내 페이지를 표현하는 HTML 문서를 가져옴으로써 웹페이지를 표시합니다. 그 다음은 이 파일을 파싱하여 실행해야하는 스크립트, 레이아웃 정보(CSS), 이미지와 동영상 같은 부가적인 정보를 위한 요청을 보냅니다. 웹브라우저는 이 리소스를 섞어 완전한 하나의 문서, 웹페이지로 만듭니다. 브라우저에서 실행 가능한 스크립트는 더 많은 정보를 후에 가져 와서 웹페이지를 업데이트 시킬수도 있습니다.
하나의 웹페이지는 hypertext 문서입니다. 이것은 몇몇 부분의 텍스트는 대게 마우스 클릭에 의해 활성화 될 수 있는 링크로서 새로운 페이지를 가져올 수 있음을 의미합니다. 링크는 유저가 user agent를 시켜 웹을 돌아다닐 수 있게 합니다. 브라우저는 이러한 지시를 HTTP 요청으로 변환하고 HTTP 응답을 해석하여 유저에게 분명한 응답을 보여주게 됩니다.
통신 채널의 반대편에서는 client의 요청에 따라 문서를 서빙하는 server가 있습니다. 서버는 사실상 단일 머신입니다. 이는 서버는 서버들의 집합일 수도 있기 때문입니다. - 로드를 분산(로드밸런싱)을 위한 서버 / 다른 컴퓨터의 캐시, DB 서버, e-커머스 서버 등의 정보를 얻어 내는 복잡한 소프트웨어의 서버 / 수요에 의해 부분적, 혹은 전체적 문서 생성을 위한 서버
서버는 반드시 단일 머신일 필요가 없고, 여러 서버 소프트웨어 인스턴스를 같은 머신위에서 호스팅 할 수 있습니다. HTTP/1.1과 HOST 헤더를 통해 같은 IP 주소를 공유하여 사용할 수도 있습니다.
웹 브라우저(client)와 서버 사이에는 수많은 컴퓨터와 머신들이 HTTP 메세지를 이어받아 전달합니다. Web stack의 여러 계층 구조 때문에 대부분의 이런 작용은 transport, network, physical layer에서 동작합니다. HTTP 계층에서는 이러한 동작들이 보이지는 않지만 성능에 상당히 큰 영향을 끼칩니다. application layer에서 transport, network, physical layer와 같은 역할을 하는 것들을 일반적으로 proxy라 합니다. proxy는 보이지 않게 동작하여 요청을 변경하지 않고 수신한 요청을 전달할 수도 있고 가시적으로 동작하며 요청을 서버로 전달하기 전 특정한 방식으로 변경합니다. Proxy는 다음과 같은 다양한 기능을 수행하게 됩니다.
Caching
캐시는 public / private 설정이 가능합니다. 예로 브라우저 캐시가 있습니다.
Filetering
안티바이러스 스캔하거나 유해 컨텐츠 차단합니다.
Load balancing
서버 과부하를 막기 위해 여러 요청을 여러 서버로 분산합니다.
Authentication
다양한 리소스에 대한 접근을 제어합니다.
Logging
히스토리 정보 저장을 허가합니다.
HTTP는 사람이 읽을수 있도록 간단하게 설계되었습니다. HTTP/2의 경우도 다소 복잡해졌지만 HTTP 메세지를 frame 별로 캡슐화하여 간결하게 유지되었습니다. HTTP 메세지는 사람이 읽고 이해하기 쉬워 개발자들에게는 쉬운 테스트를 제공하고 처음 접하는 사람에게도 진입 장벽이 낮습니다.
HTTP/1.0에서 소개된 HTTP 헤더로 인해 HTTP는 확장하고 실험하기 쉽게 되었습니다. 새로운 기능은 client와 server에서 새로운 헤더의 semantic에 대해 간단한 합의만 이루어 진다면 쉽게 추가 될 수 있습니다.
HTTP는 stateless입니다. 동일한 연결 위에서 성공적으로 수행된 요청 사이에는 어떠한 링크도 없습니다. 이로 인해 특정페이지에서 일관된 상호작용을 하고자하는 유저에게는 문제가 됩니다. e 커머스 쇼핑 바구니가 그 예입니다. 하지만 HTTP의 핵심은 stateless이지만 HTTP 쿠키를 통해 stateful한 session을 사용할 수 있습니다. Header 확장성을 사용함으로써, HTTP 쿠키는 workflow에 추가되어 같은 context 공유를 위해 각각의 HTTP 요청에 세션을 만들 수 있습니다.
Header 확장성 -> HTTP 쿠키 등장 -> Context 공유
connection은 transport layer에서 제어되므로 근본적으로 HTTP 밖의 영역입니다. HTTP는 연결을 위한 전송 프로토콜을 요구하지는 않습니다. 하지만 신뢰할 수 있고 메세지 손실이 없는(최소 오류는 표시) 연결은 필요로 합니다. 인터넷의 가장 일반적인 두 전송 프로토콜중 TCP는 신뢰할 수 있지만 UDP는 그렇지 못합니다. 따라서 HTTP는 연결 기반인 TCP 표준에 의존하게 됩니다.
Client와 Server에서 HTTP 요청/응답이 일어나기 전 몇번의 왕복 작업이 필요한 TCP connection이 만들어져야 합니다. HTTP/1.0에서 디폴트는 각각의 HTTP 요청/응답에 대해 다른 TCP 연결을 사용합니다. 이런 방식은 여러 요청을 연속해서 보내게 되는 경우 단일 TCP 연결을 공유하는 것에 비해 비효율적입니다.
이러한 결함 개선을 위해, HTTP/1.1에서는 (구현에 어려운) pipelining 과 persistent connections이 소개되었습니다. 기본적인 TCP 연결은 Connection 헤더를 통해 부분적으로 제어가 가능합니다. HTTP/2는 단일 연결에서 메세지를 다중 전송(multiplex)할 수 있도록 진화되어, 연결을 지속가능하며 효율적으로 유지되도록 도움이 되었습니다.
HTTP에 보다 적절한 좋은 전송 프로토콜을 위한 설계는 계속해서 실험이 진행되고 있습니다. 예로 구글은 보다 신뢰성있고 효율적인 전송 프로토콜을 위해 UDP 기반 QUIC에 대해 실험중입니다.
HTTP의 확장 가능성은 꾸준히 웹의 더 많은 컨트롤과 기능들을 허용하게 했습니다. 캐시나 인증 메서드는 HTTP 역사의 초기부터 다뤄진 기능입니다. 하지만 origin 의 제약을 완화시키는 것은 2010년대에 와서야 가능해졌습니다.
다음은 HTTP를 통해 제어할수 있는 일반적인 기능입니다.
Caching
HTTP를 통해 문서가 캐시되는 것에 대해 제어가 가능합니다. 서버는 무엇을 캐시할지, 얼마나 유지할지에 대해 proxy와 client에 지시할 수 있습니다. client는 저장된 문서를 무시하도록 cache proxy에게 지시할 수 있습니다.
Relaxing the origin constraint
스누핑과 프라이버시 침해를 막기 위해, 웹 브라우저는 웹사이트간 엄격한 분리를 강제합니다. same origin 으로부터의 페이지만 웹 페이지의 전체 정보에 접근할 수 있습니다. 이런 제약은 서버에는 부담이지만 서버 측에서의 HTTP 헤더를 통해 이런 제약을 완화시켜, 다른 도메인으로부터 문서를 가져오는 것을 허용할 수 있게 합니다. 하지만 이것은 보안 문제를 야기하기도 합니다. 이에 대한 자세한 설명은 Same origin policy, CORS 를 참조하시면 됩니다.
Authentication
몇몇 페이지는 보호되어 특정 유저에게만 접근을 허가할 수 있습니다. 기본 인증은 HTTP에 의해 제공되는데 WWW-Authentication과 유사한 헤더의 사용, 혹은 HTTP 쿠키를 사용한 특정한 세션의 설정을 통해 이루어집니다.
Proxy and tunneling
서버나 클라이언트는 종종 인트라넷에 있어 다른 컴퓨터에게는 실제 IP를 숨기기도 합니다. 이럴 경우 HTTP 요청은 proxy를 통해 가서 네트워크 장벽을 건너가게 됩니다. 모든 proxy가 HTTP proxy는 아닙니다. 예로 SOCKS 프로토콜은 더 낮은 low level에서 동작합니다. ftp와 같은 다른 프로토콜이 이러한 proxy에 의해 다뤄집니다.
Session
HTTP 쿠키 사용은 서버의 상태를 요청과 연결할 수 있게 합니다. 이것은 기본적인 HTTP는 state-less 프로토콜이지만 세션을 생성해주게 됩니다. 이것은 e커머스 장바구니 이외에도 사용자 설정을 허가하는 어떤 사이트에서라도 굉장히 유용하게 동작합니다.
클라이언트가 서버와 통신하고 싶을 때, 서버와 직접 혹은 프록시를 통해 다음 단계를 수행하게 됩니다.
TCP 연결을 설정합니다. TCP 연결은 하나 혹은 여러개의 요청을 보내고 응답을 받아내는데 사용됩니다. 클라이언트는 새로운 연결을 열거나 이미 있는 커넥션을 사용하거나 서버에 여러 TCP 연결을 열 수 있습니다.
HTTP 메세지를 전송합니다. HTTP/2 이전의 HTTP 메세지는 사람이 읽을 수 있습니다. HTTP/2에서는 이런 간단한 메세지가 frame 속으로 캡슐화되어 직접적으로 읽을수 없게 하지만 기본적인 원리는 동일합니다. 다음은 예시입니다.
메세지의 요소에 대한 설명은 다음 챕터에서 설명됩니다.
GET / HTTP/1.1
Host: johnie-yeo.github.io/hello/back-end/2020/04/08/REST
Accept-Language: ko
서버가 보낸 응답을 읽습니다. 예로
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
연결을 닫거나 다른 요청을 위해 연결을 재사용합니다.
만약 HTTP pipelining이 활성화 되었다면, 몇몇 요청은 첫번째 응답이 완전히 오는 것을 기다리지 않고 요청을 보낼 수 있습니다. HTTP pipelining은 오래된 소프트웨어와 최신 버전이 공존하고 있는 기존의 네트워크에서는 구현되기 어렵다는게 입증되었습니다. HTTP pipelining은 단일 프레임 내에서 활발한 다중 요청을 보내는 HTTP/2에서 대체되고 있습니다.
HTTP/1.1과 그 이전에 정의된 HTTP 메세지는 사람이 읽을 수 있는 형태였습니다. HTTP/2에서는 이 메세지들은 binary structure인 frame 속으로 내장되어 헤더의 압축과 다중화 같은 최적화가 가능해졌습니다. HTTP/2에서는 기존의 HTTP 메세지의 일부분만 전송되지만 각 메세지의 의미는 변하지 않고, 클라이언트는 가상으로 기존의 HTTP/1.1 요청을 재구성합니다. 따라서 HTTP/2 메세지를 HTTP/1.1 메세지로 이해하는것은 유용하게 됩니다.
HTTP 메세지에는 두가지 유형이 있습니다. request와 response. 각각은 서로다른 특성이 있습니다.
HTTP 요청의 예입니다.

요청은 다음 요소들로 구성됩니다.
HTTP method
일반적으로 GET, POST와 같은 동사 혹은 OPTIONS , HEAD와 같은 명사이며 클라이언트가 원하는 형태의 동작을 정의합니다. 보통 클라이언트는 GET을 통해 리소스를 가져오거나 POST를 통해 HTML form의 값을 post하려고 하지만, 경우에 따라 다른 동작이 요구되기도 합니다.
Path
가져오고자 하는 리소스의 경로로서 예를 들어 프로토콜(http://), 도메인(developer.mozilla.org), TCP 포트(80) 과 같은 요소들을 제거한 리소스의 URL입니다.
HTTP 프로토콜의 버전
헤더(optional)
서버의 추가적인 정보를 전달합니다.
body(optional)
POST 와 같은 메서드에서 사용되고 응답메세지에서와 비슷하게 보내는 리소스를 포함합니다.
응답의 예입니다.

응답은 다음 요소로 구성됩니다.
사용되는 HTTP 프로토콜의 버전.
Status code
요청이 성공했는지, 실패했는지와 그 이유를 나타냅니다.
Status message
상태코드의 간단한 설명을 나타내지만 아무런 영향력은 없습니다.
HTTP Headers
요청헤더와 비슷한 역할을 담당합니다.
Body(optional)
가져온 리소스를 포함한 본문입니다.
HTTP 기반의 가장 일반적으로 사용되는 API는 XMLHTTPRequest API로 user agent와 서버간 데이터 교환에 사용할 수 있습니다. 최신 Fetch API는 유사한 기능을 보다 강력하고 유연한 기능들로 제공합니다.
다른 API인 server-sent events는 단방향 서비스로 서버가 이벤트를 클라이언트에게 HTTP를 전송 메커니즘으로 사용해 보내는 것입니다. Event Source 인터페이스를 사용하여 클라이언트는 연결을 맺고 이벤트 핸들러를 설정합니다. 클라이언트 브라우저는 HTTP 스트림으로 온 메세지를 자동으로 적절한 Event객체로 변환하여, 이벤트의 등록된 type이 알려진 경우 이벤트 핸들러에게 이를 전달합니다. 혹은 특정 type 이벤트 핸들러가 설정되지 않은 경우에는 onmessage 이벤트 핸들러에게 이벤트를 전달합니다.
HTTP는 사용이 쉬운 확장 가능한 프로토콜입니다. client-server 구조와 헤더를 쉽게 추가하는 능력이 합쳐져 HTTP가 웹의 확장된 수용력과 함께 발전할 수 있게 합니다.
HTTP/2가 HTTP 메세지를 프레임 내로 내장하여 성능향상을 위해 복잡함을 더했지만 메세지의 기본 구조는 HTTP/1.0에서와 동일합니다. 세션의 흐름은 간단하게 남아, 간단한 HTTP 메세지 모니터를 통해 조사하고 디버그하는 것을 가능하게 해줍니다.
Reference